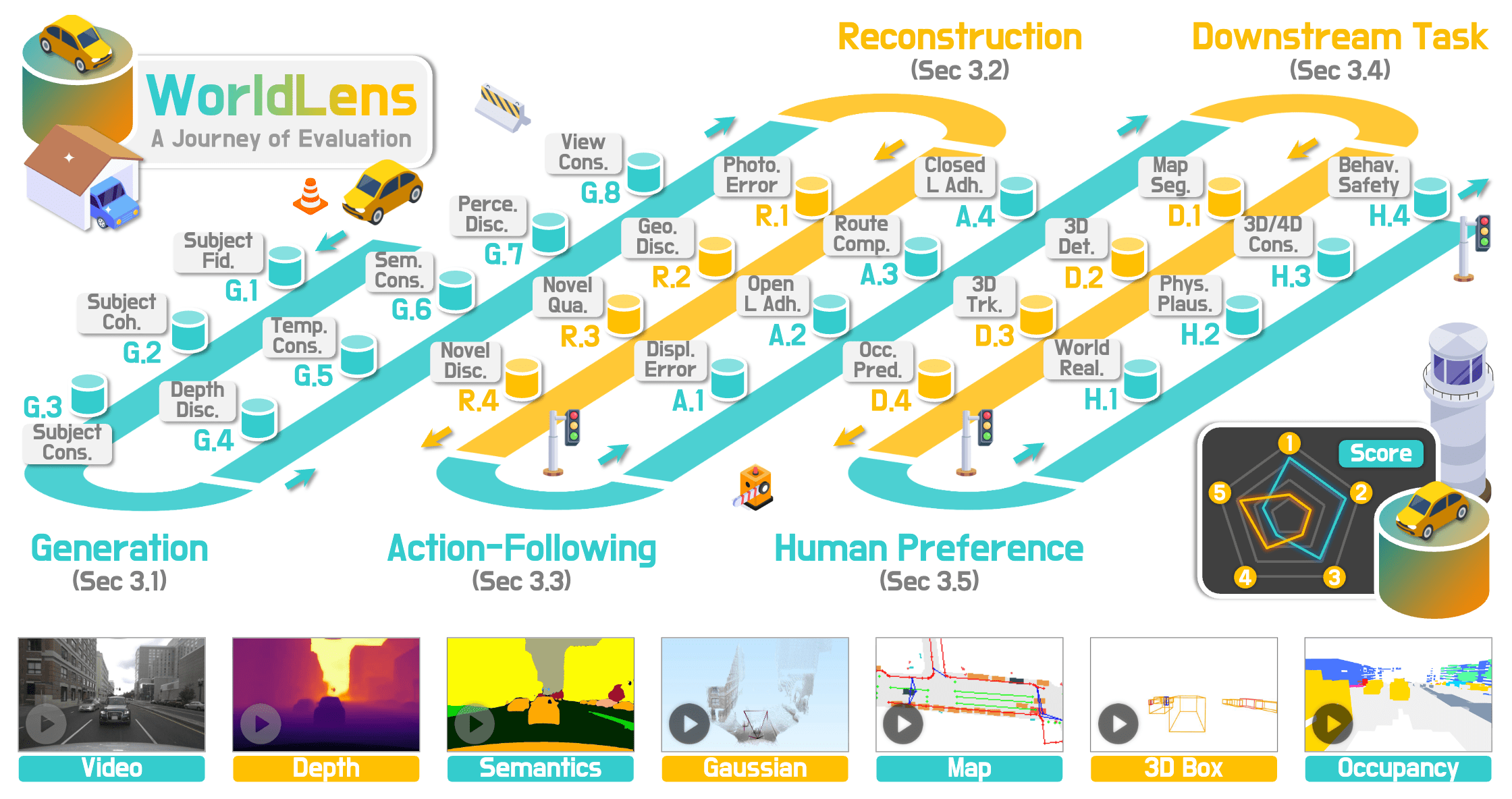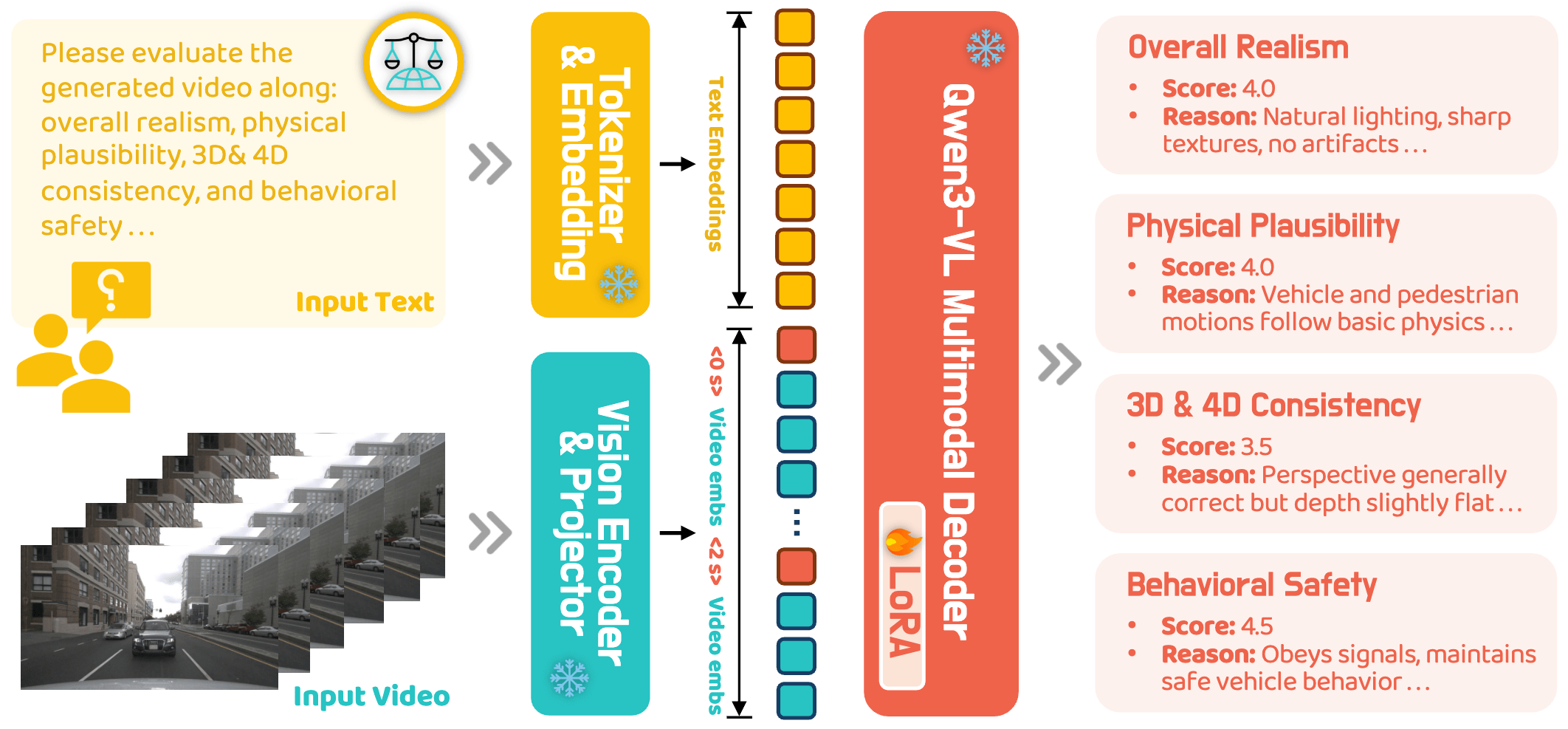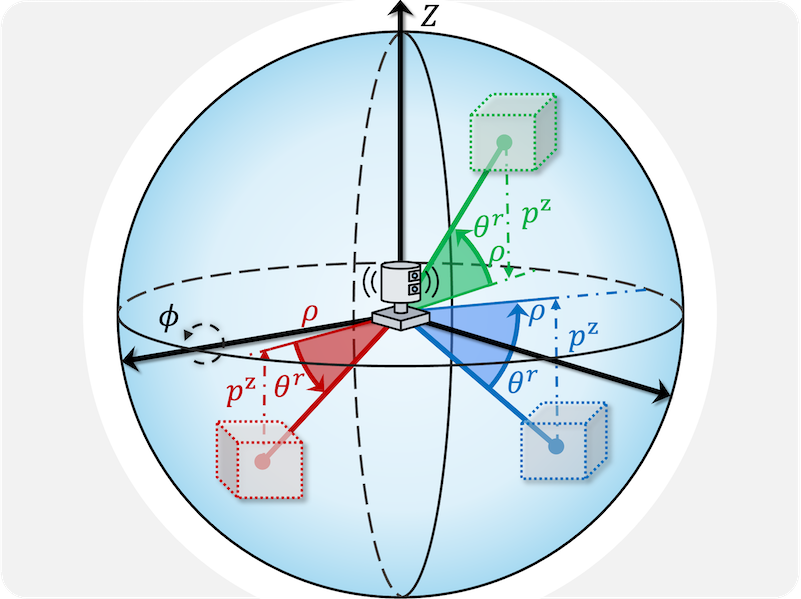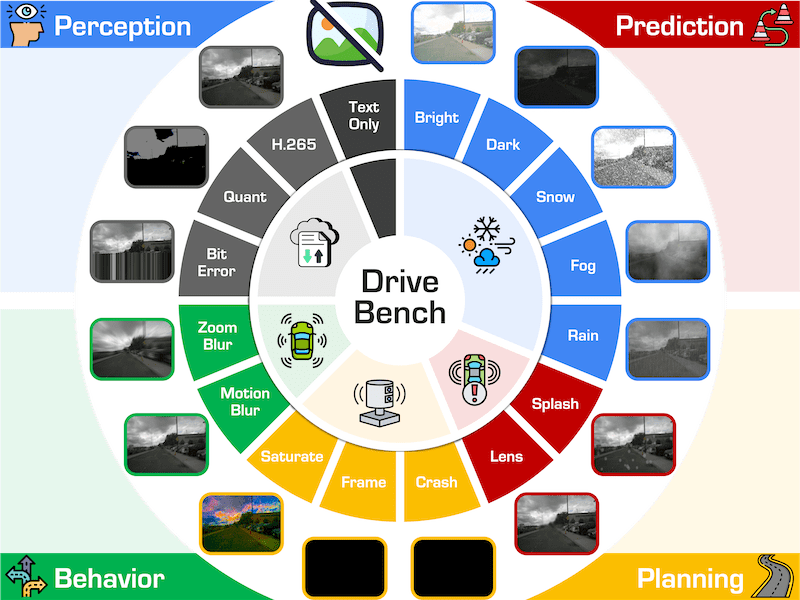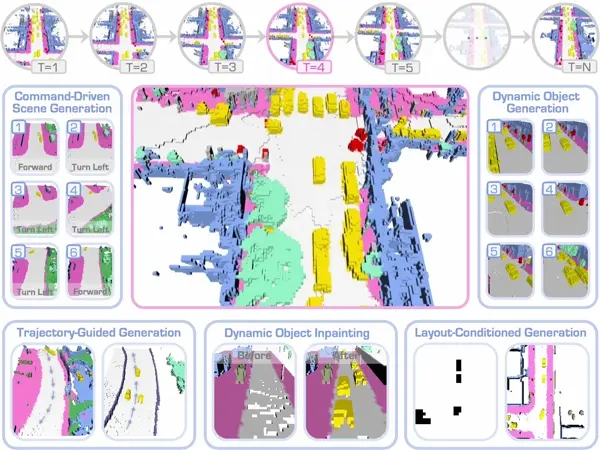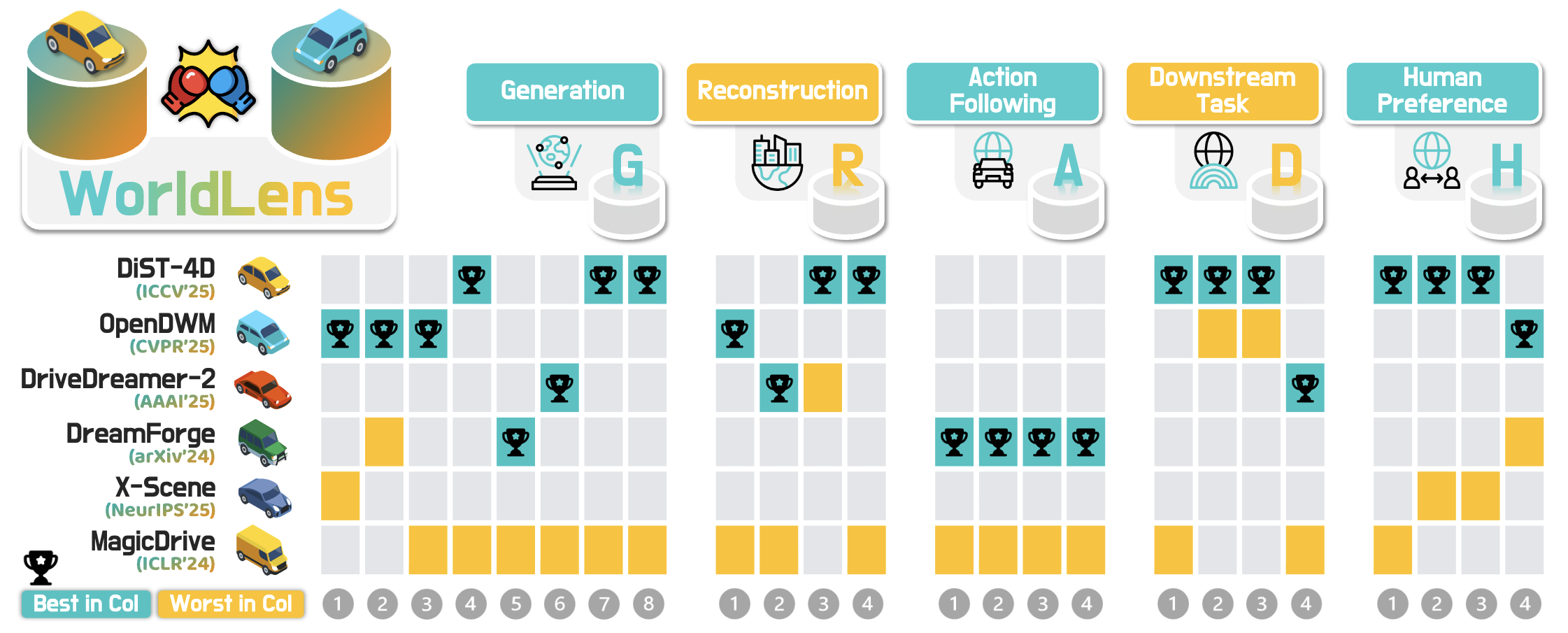
 Generation
Generation
measuring whether a model can synthesize visually realistic, temporally stable, and semantically consistent scenes. Even state-of-the-art models that achieve low perceptual error (e.g., LPIPS, FVD) often suffer from view flickering or motion instability, revealing the limits of current diffusion-based architectures.