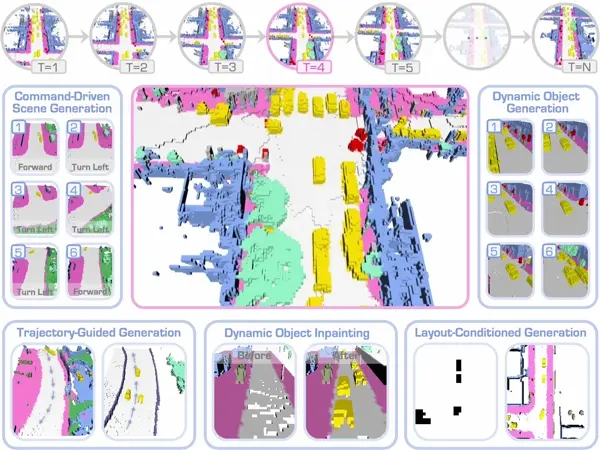
World modeling has become a cornerstone in AI research, enabling agents to understand, represent, and predict the dynamic environments they inhabit.
While prior work largely emphasizes generative methods for 2D image and video data, they overlook the rapidly growing body of work that leverages native 3D and 4D representations such as RGB-D imagery, occupancy grids, and LiDAR point clouds for large-scale scene modeling.
This survey reviews 3D and 4D world models — models that learn, predict, and simulate the geometry and dynamics of real environments from multi-modal signals.
We unify terminology, scope, and evaluation, and organize the space into three complementary paradigms by representation: VideoGen (image/video-centric),
OccGen (occupancy-centric), and LiDARGen (point-cloud-centric).
What it is. An image/video-centric world model that generates or predicts
photorealistic, temporally consistent frames (single- or multi-view) conditioned on past context and optional controls.
Typical inputs: past frames, poses/camera intrinsics-extrinsics, text/route/action hints.
Video SynthesisFuture PredictionWhat-If SimulationMulti-View Generation
What it is. An occupancy-centric world model that represents scenes as 3D/4D occupancy
fields (e.g., voxel grids with semantics), enabling geometry-aware perception, forecasting, and simulation.
What it is. A point-cloud-centric world model that learns high-fidelity geometry and
dynamics directly from LiDAR sweeps, suitable for robust 3D understanding, data generation, and sensor-faithful simulation.
Typical inputs: past LiDAR sweeps, ego trajectory, calibration; optional scene priors.
Point Cloud SynthesisFuture SweepsTrajectory-ConditionedPhysics-Aware
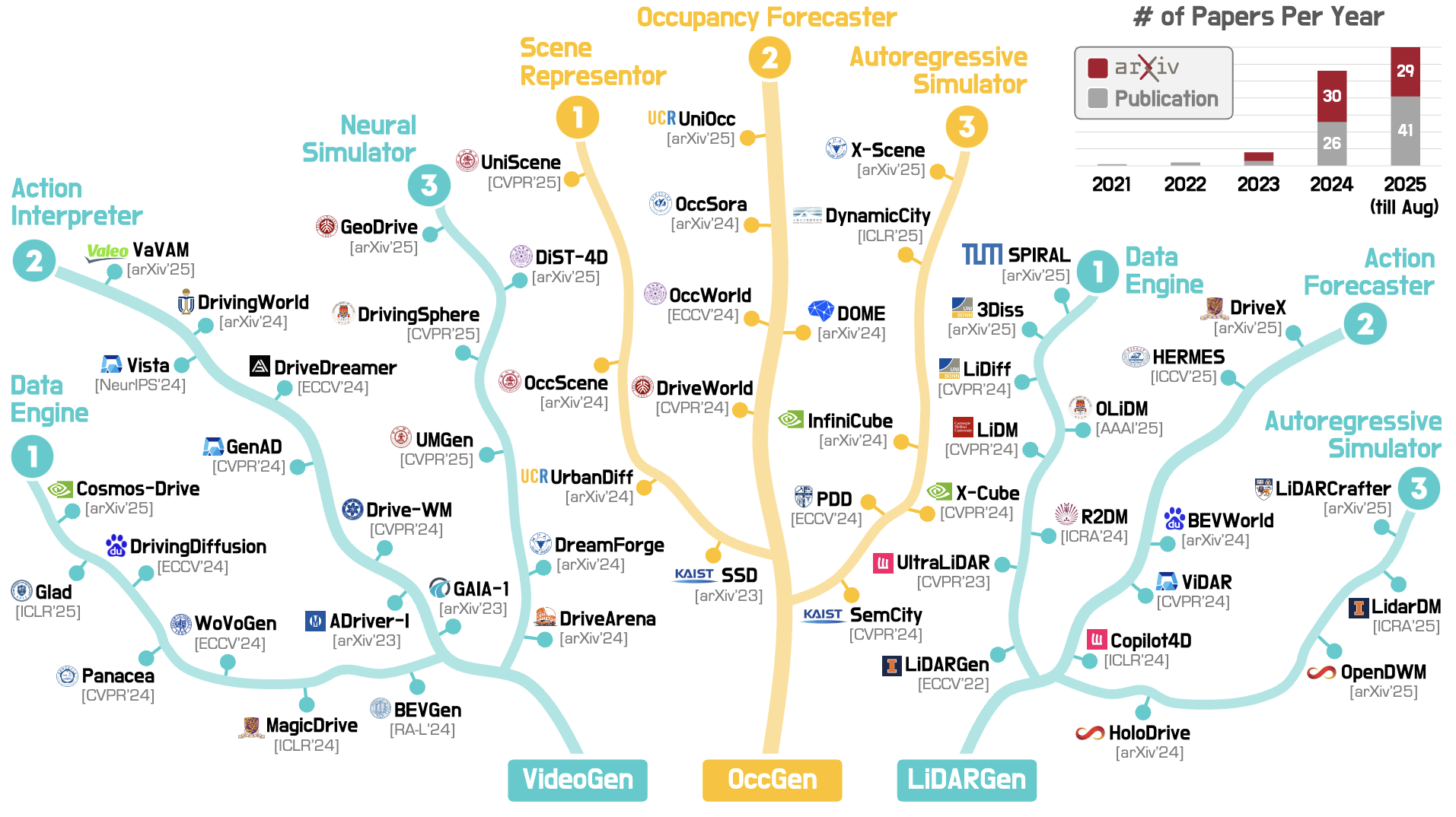
A Hierarchical Taxonomy
We establish precise definitions, introduce a structured taxonomy spanning VideoGen, OccGen, and LiDARGen approaches, and systematically summarize datasets and evaluation metrics tailored to 3D/4D settings.
Together, these models provide the foundation for simulation, planning, and embodied intelligence in complex environments.
World Model Categorization
We categorize 3D/4D world models into four functional types. They differ in how historical observations are
leveraged, which conditioning signals are provided,
and whether models operate in open-loop or closed-loop settings.
Type 1
Data Engines
Generate diverse 3D/4D scenes from geometric and semantic cues, optionally with action conditions.
Focus on plausibility and diversity for large-scale data augmentation and scenario creation.
Forecast future 3D/4D world states from historical observations under given action conditions.
Enable action-aware forecasting for planning, behavior prediction, and policy evaluation.
Iteratively simulate closed-loop agent-environment interactions by generating successive scene states.
Support interactive simulation for autonomous driving, robotics, and immersive XR training.
Recover complete and coherent 3D/4D scenes from partial, sparse, or corrupted observations.
Facilitate interactive tasks such as high-fidelity mapping and digital twin restoration.
Together, these four categories outline the functional landscape of 3D/4D world modeling.
While all aim to produce physically and semantically coherent scenes, they differ in how they
leverage past observations, conditioning signals, and interaction loops—supporting applications
from large-scale data synthesis and policy evaluation to interactive simulation and scene restoration.
Generated 3D & 4D Contents
VideoGen
Reference
Reference
Reference
OccGen
Sample 1
LiDARGen
(click to expand)
Collections
Video Generation
🔎
0 items
Occupancy Generation
🔎
0 items
LiDAR Generation
🔎
0 items
Contributors
Lingdong Kong
Core Contributor, Project Lead
Wesley Yang
Core Contributor
Jianbiao Mei
Core Contributor
Youquan Liu
Core Contributor
Ao Liang
Core Contributor
Dekai Zhu
Core Contributor
Dongyue Lu
Core Contributor
Wei Yin
Core Contributor
Xiaotao Hu
Contributor, VideoGen
Mingkai Jia
Contributor, VideoGen
Junyuan Deng
Contributor, VideoGen
Kaiwen Zhang
Contributor, VideoGen
Yang Wu
Contributor, LiDARGen
Tianyi Yan
Contributor, LiDARGen
Shenyuan Gao
Contributor, VideoGen
Song Wang
Contributor, OccGen
Linfeng Li
Contributor, OccGen
Liang Pan
Advisor
Yong Liu
Advisor
Jianke Zhu
Advisor
Wei Tsang Ooi
Advisor
Steven C. H. Hoi
Advisor
Ziwei Liu
Advisor
Related Projects
WorldLens: Full-Spectrum Evaluations of Driving World Models
VBench: Benchmark Suite for Video Generative Models
VBench++: Versatile Video Generation Benchmark
VLA for Autonomous Driving: Past, Present, and Future
LiDARCrafter: Dynamic 4D World Modeling from LiDAR Sequences