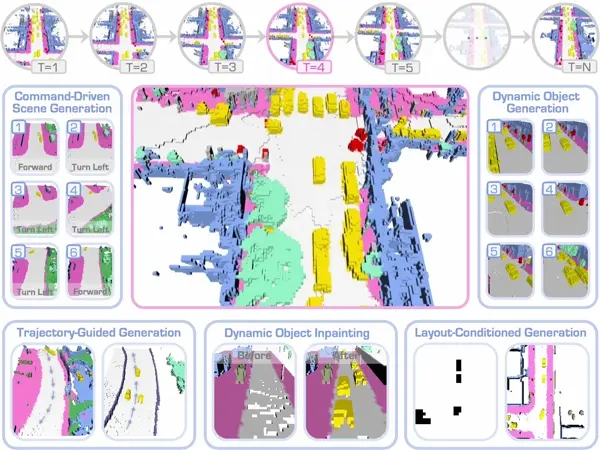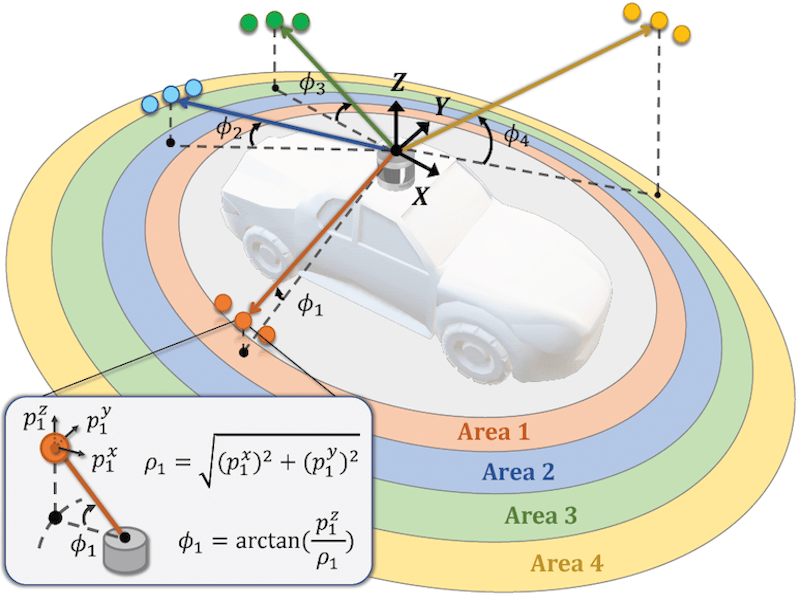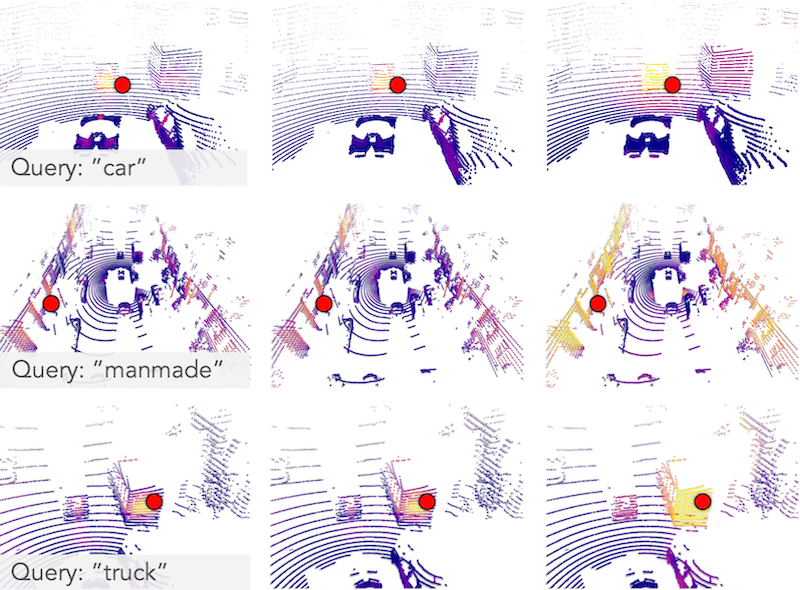

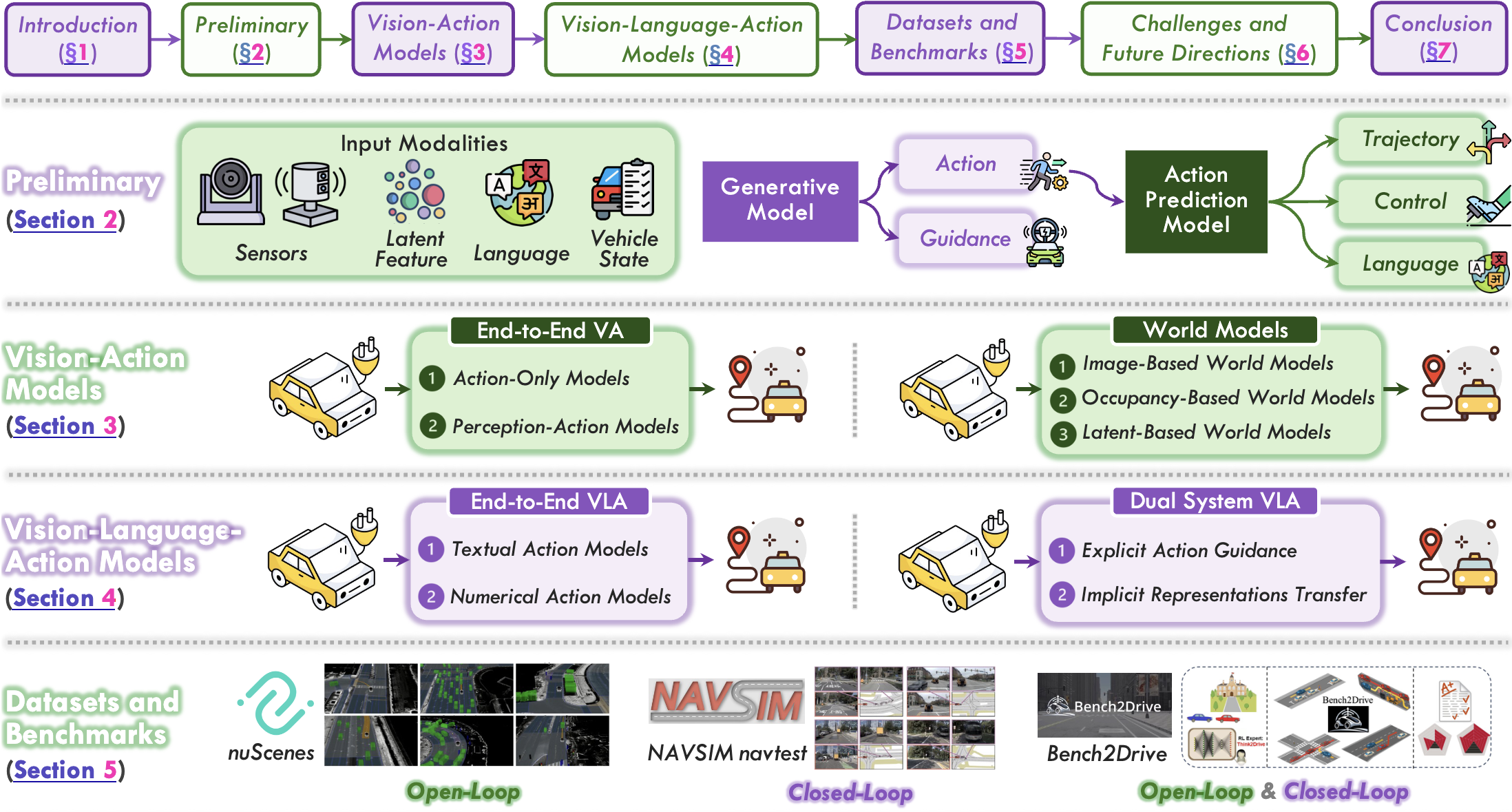

Vision-Action (VA) Models
A vision-centric driving system that directly maps raw sensory observations to driving actions, thereby avoiding explicit modular decomposition into perception, prediction, and planning. VA models learn end-to-end policies through imitation learning or reinforcement learning.