| Code Generation |
| 1 |
SWE-bench |
ICLR'24 |
Code Gen. |
2,294 real GitHub issues; Verified split (500 problems). |
|
| 2 |
SWE-agent |
arXiv'24 |
Code Gen. |
Agent–computer interface paradigm for coding. |
|
| 3 |
OpenHands |
ICLR'25 |
Code Gen. |
Open platform for generalist coding agents. |
|
| 4 |
SWE-bench Pro |
arXiv'25 |
Code Gen. |
1,865 enterprise problems; best score 23%. |
|
| 5 |
SWE-EVO |
arXiv'25 |
Code Gen. |
Software evolution benchmark; best score 25%. |
|
| Paper-to-Code |
| 6 |
FunSearch |
Nature'24 |
Paper-to-Code |
New cap-set solutions; evolutionary program search. |
|
| 7 |
SciCode |
arXiv'24 |
Paper-to-Code |
Research-level coding across math, physics, chemistry. |
|
| 8 |
PaperBench |
arXiv'25 |
Paper-to-Code |
20 ICML'24 papers; 8,316 gradable subtasks. |
|
| 9 |
PaperCoder |
arXiv'25 |
Paper-to-Code |
3-stage multi-agent; ML papers to code repos. |
|
| 10 |
ResearchCodeBench |
arXiv'25 |
Paper-to-Code |
212 novel ML tasks; best 37.3% (Gemini-2.5-Pro). |
|
| 11 |
SciReplicate-Bench |
arXiv'25 |
Paper-to-Code |
100 tasks from 36 NLP papers; 39% ceiling. |
|
| Experiment Execution & Orchestration |
| 12 |
BioPlanner |
arXiv'23 |
Execution |
Biological protocol planning evaluation. |
|
| 13 |
CRISPR-GPT |
arXiv'24 |
Execution |
Gene-editing experiment design assistance. |
|
| 14 |
DS-Agent |
arXiv'24 |
Execution |
End-to-end data science workflow automation. |
|
| 15 |
MLE-Bench |
arXiv'24 |
Execution |
75 Kaggle competitions benchmark. |
|
| 16 |
MLAgentBench |
arXiv'24 |
Execution |
13 ML experimentation tasks benchmark. |
|
| 17 |
MLR-Copilot |
arXiv'24 |
Execution |
IdeaAgent + ExperimentAgent dual-agent pipeline. |
|
| 18 |
AIDE |
arXiv'25 |
Execution |
SOTA on MLE-Bench + RE-Bench; tree search in code space. |
|
| 19 |
AlphaEvolve |
arXiv'25 |
Execution |
LLM-generated mutations + automated evaluators. |
|
| 20 |
AutoReproduce |
arXiv'25 |
Execution |
Paper lineage algorithm for experiment reproduction. |
|
| 21 |
CURIE |
arXiv'25 |
Execution |
Rigorous automated experimentation framework. |
|
| 22 |
MLGym |
arXiv'25 |
Execution |
AI research agent gym benchmark. |
|
| 23 |
MLR-Bench |
arXiv'25 |
Execution |
201 tasks (NeurIPS/ICLR/ICML); 80% fabrication rate. |
|
| 24 |
Execution-Grounded |
arXiv'26 |
Execution |
69.4% vs 48.0% GRPO; parallel GPU search. |
|
| 25 |
Learn to Discover |
arXiv'26 |
Execution |
Test-time training + RL; math, GPU kernel, biology. |
|
| 26 |
SciNav |
arXiv'26 |
Execution |
Pairwise tree-search branch selection. |
|
| 27 |
FrontierScience |
arXiv'26 |
Execution |
Expert-level tasks; Olympiad + PhD difficulty. |
|
| 28 |
AutoTTS |
arXiv'26 |
Execution |
Coding-agent discovery of test-time scaling strategies |
|
| Code Correctness and Reproducibility Assessment |
| 29 |
DiscoveryBench |
arXiv'24 |
Analysis |
Data-driven insight extraction benchmark. |
|
| 30 |
DiscoveryWorld |
arXiv'24 |
Analysis |
120 tasks; 8 topics; 3 difficulty levels. |
|
| 31 |
InfiAgent-DABench |
arXiv'24 |
Analysis |
End-to-end data analysis workflow benchmark. |
|
| 32 |
ScienceAgentBench |
arXiv'24 |
Analysis |
Rigorous data-driven scientific discovery assessment. |
|
| 33 |
LAB-Bench |
arXiv'24 |
Execution |
Multi-domain biology research task benchmark. |
|
| 34 |
KernelBench |
arXiv'25 |
Execution |
GPU kernel generation benchmark. |
|
| 35 |
TritonBench |
arXiv'25 |
Execution |
Triton operator generation benchmark. |
|
| 36 |
AstaBench |
arXiv'25 |
Execution |
2,400+ problems; multi-domain scientific research. |
|
| 37 |
ResearchClawBench |
arXiv'25 |
Execution |
Scientist-aligned workflow benchmark. |
|
| 38 |
EXP-Bench |
ICLR'26 |
Execution |
461 tasks from 51 AI papers. |
|
| 39 |
PostTrainBench |
arXiv'26 |
Execution |
LLM post-training automation benchmark. |
|
| 40 |
EvoDS |
arXiv'26 |
Execution |
Self-evolving data-science agent; skill learning + context mgmt |
|
| 41 |
MLReplicate |
arXiv'26 |
Analysis |
End-to-end ML reproducibility benchmark for autonomous systems |
|
| 42 |
BeyondSWE |
arXiv'26 |
Execution |
500 instances / 246 repos; cross-repo, domain-fix, migration, doc2repo |
|





















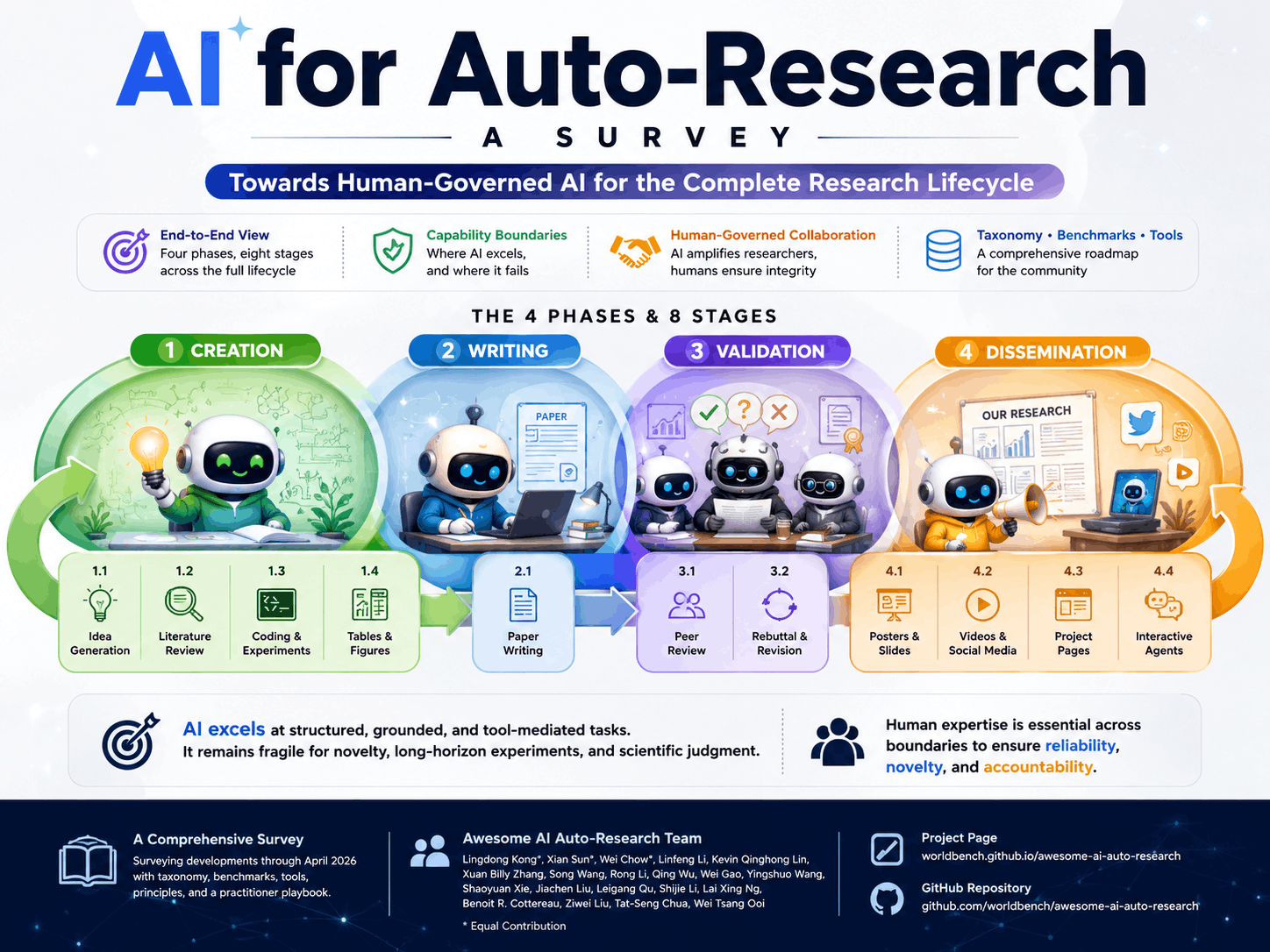

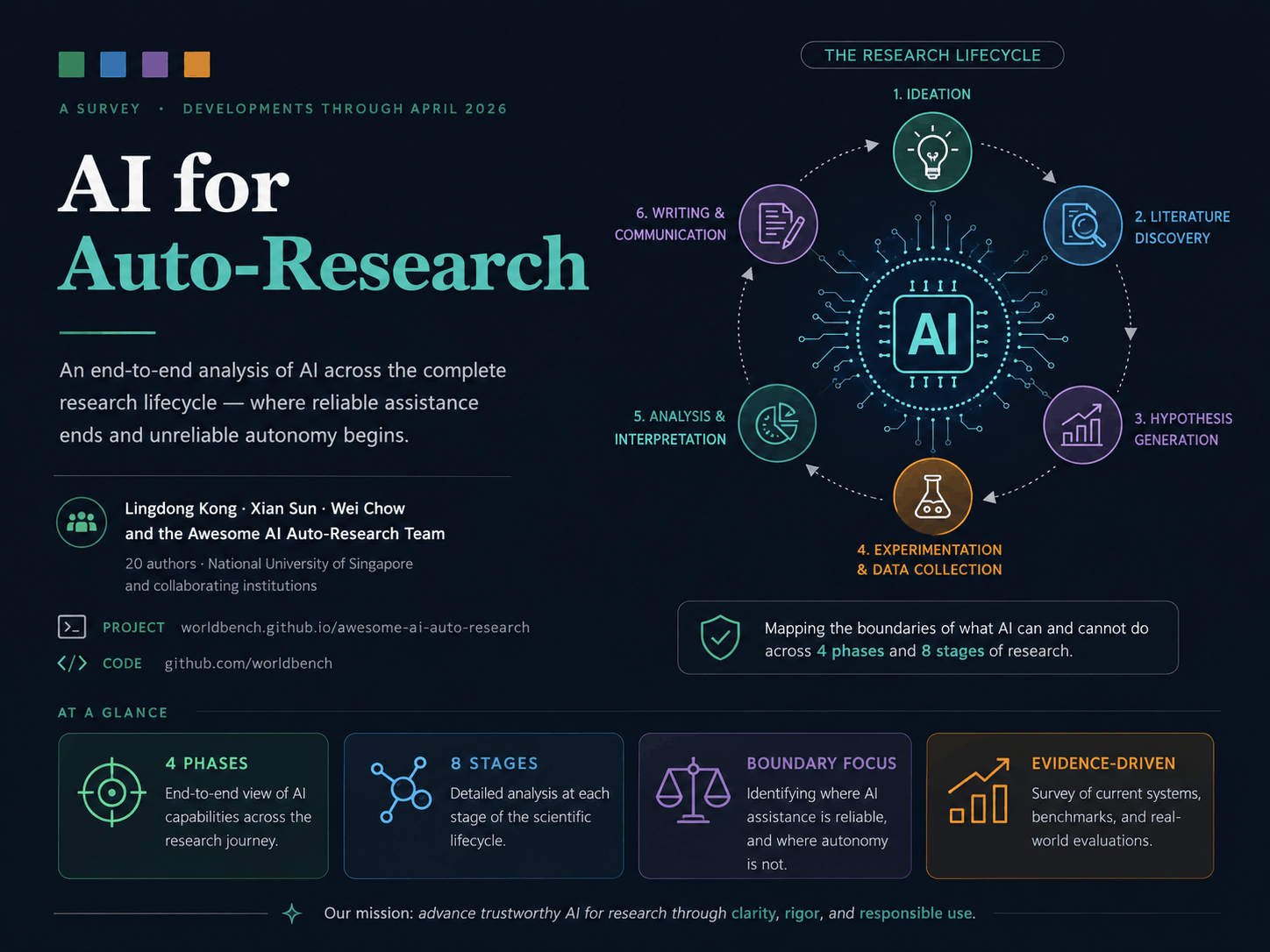

























Paper2Social
Posts crafted from the survey across X, LinkedIn, Reddit, and Mastodon — each tuned to its platform's tone, length, and audience.
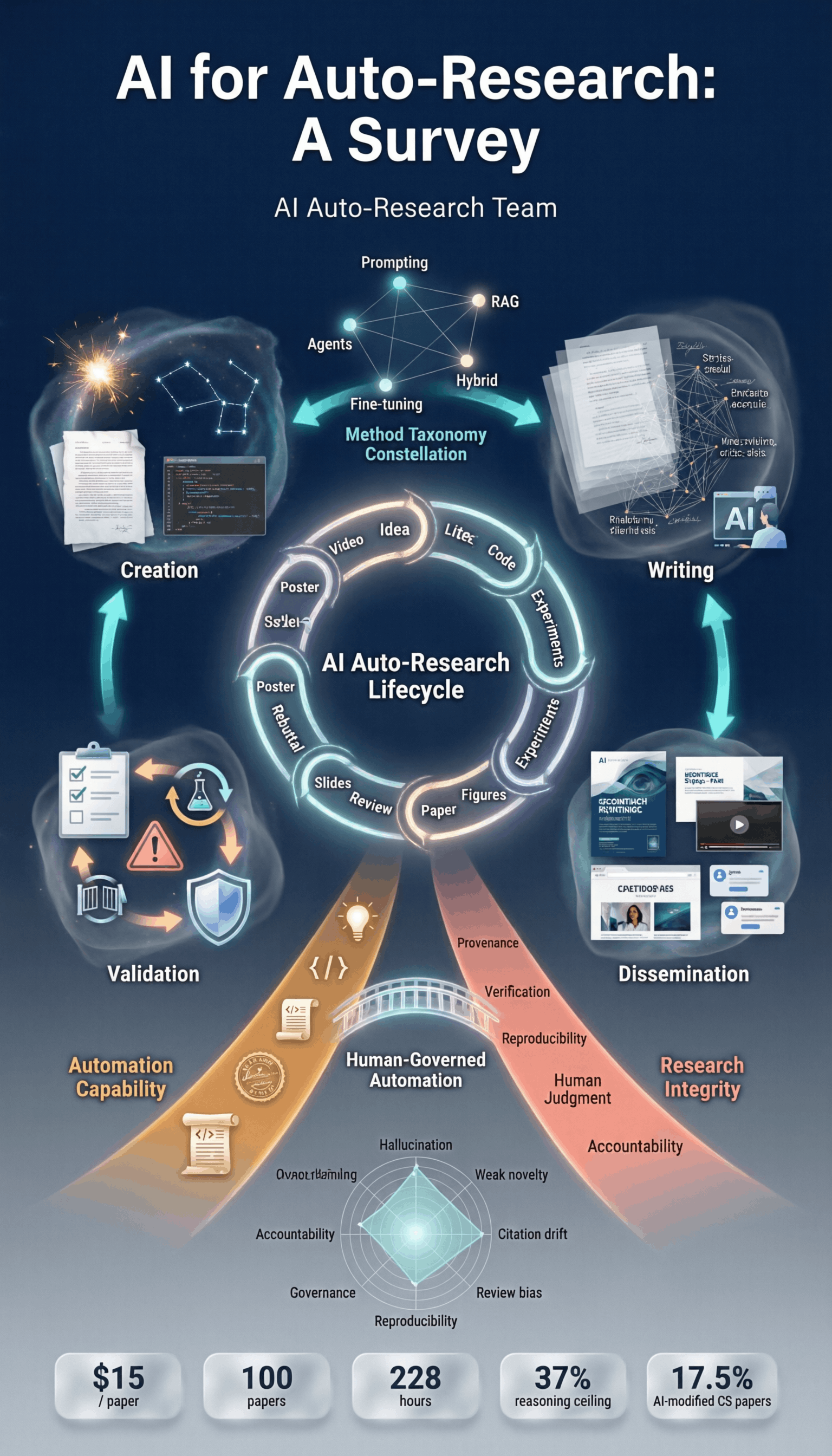
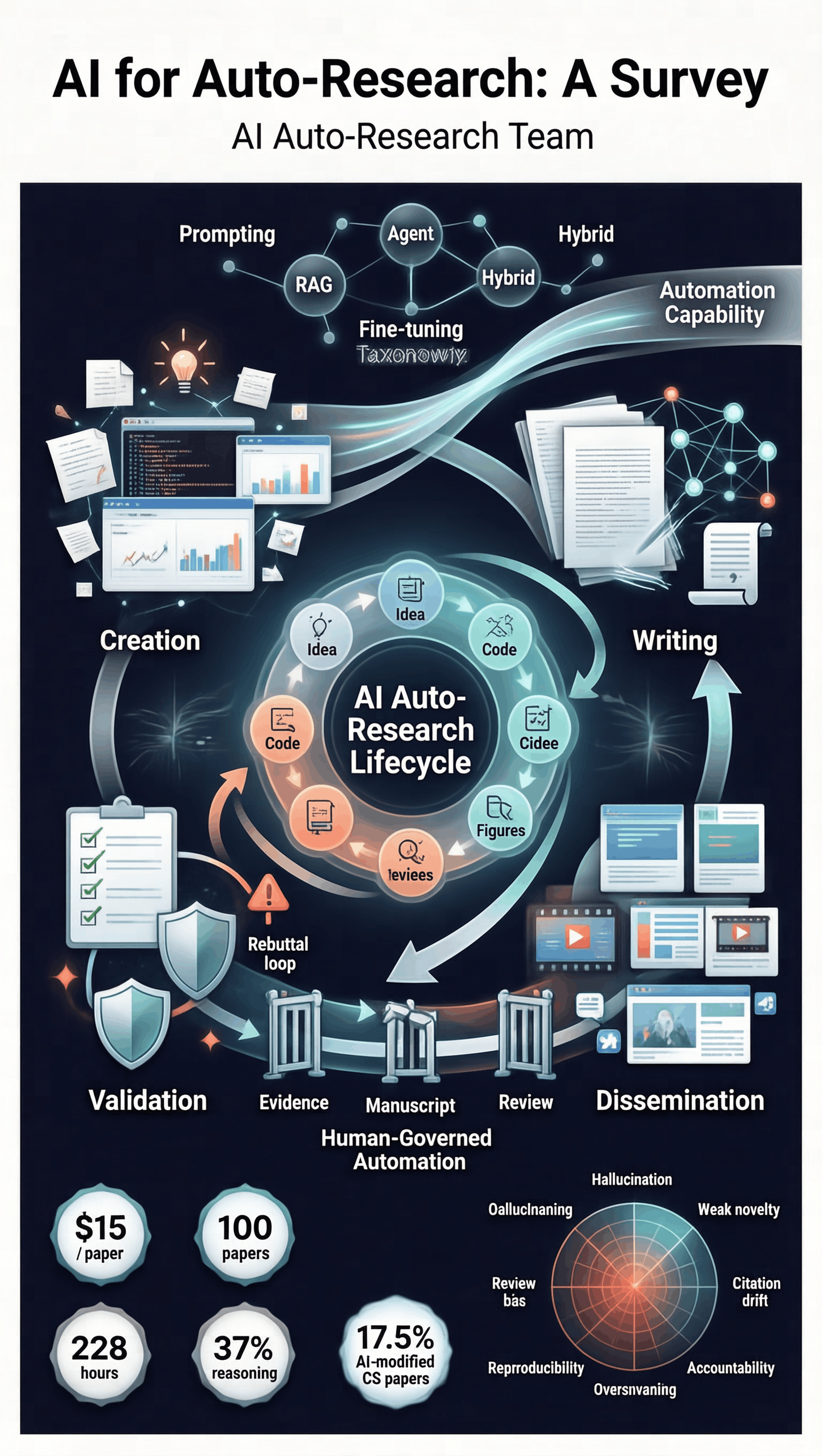
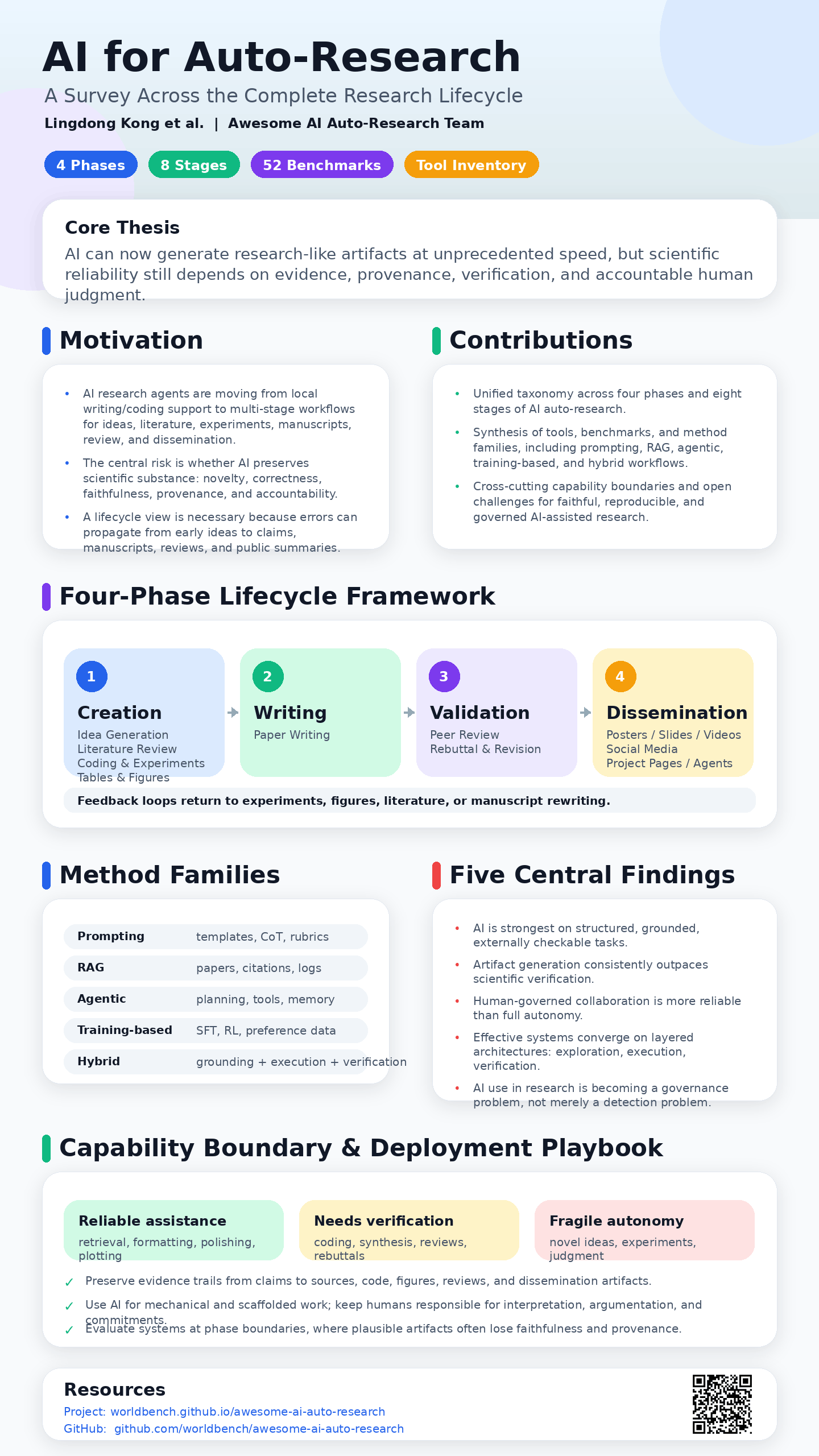
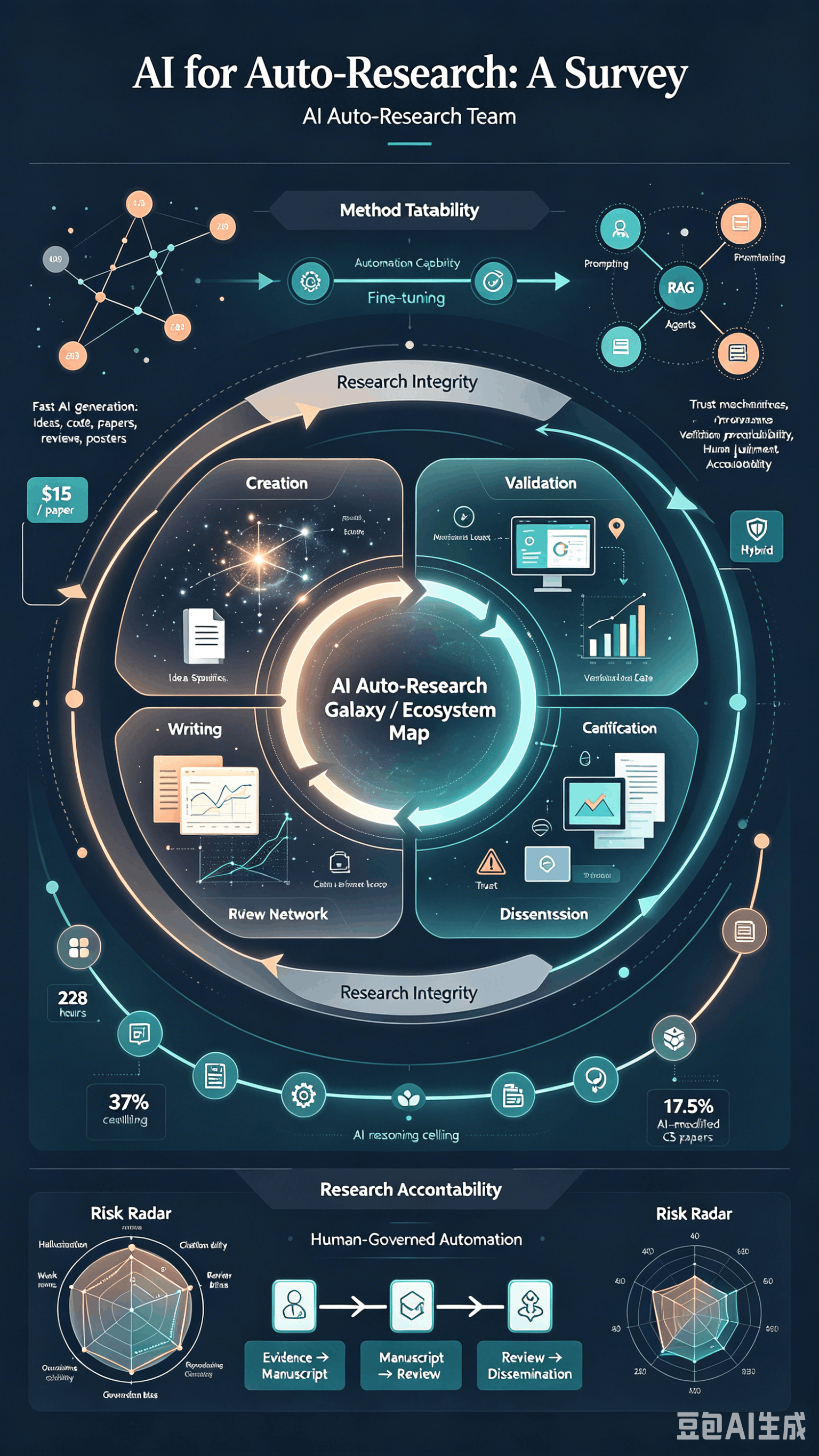
A fully automated AI system can now generate a research paper for as little as $15. But under pressure, every frontier LLM still fabricates results. The capability-vs-integrity tension is real. Our survey of 200+ papers maps the boundary. #AIforScience #LLM
Three findings every research lab should know in 2026: 1. AI handles the mechanical — but research-level code plateaus near 37% success. 2. 95.8% of rejected papers are misclassified as acceptable by LLM reviewers. 3. The most successful auto-research systems converge on a 3-layer architecture: exploration, execution, verification. Read the full survey →
[D] We surveyed 200+ AI auto-research papers. Here's what works, what doesn't, and what to do about it. Tools are now generating papers in 2.3 hours at $15. But the failure modes are getting harder to see — not easier. Ideation looks novel until execution; LLM reviewers are systematically lenient; cost decouples from quality past a modest budget. Full breakdown of the capability boundary, by stage. AMA in comments.
2/8 The ideation-execution gap is real: LLM ideas score 5.38 on novelty → drop to 3.41 after a human implements them. Brilliant on paper, brittle in practice. We see the same shape across stages.
Up to 17.5% of CS papers already carry detectable AI modification. The community needs to shift from detection (a losing race) to declaration. We propose stage-by-stage disclosure norms in the playbook. #AIethics #scicomm
Excited to release the Practitioner's Playbook — a stage-by-stage guide on what to delegate to AI and what to keep under human ownership. For each of the 8 research stages: ✅ delegate, ⚠️ retain, ❌ key risk. Built from controlled experiments and 250+ papers. Free + open. @worldbench